C++ マルチスレッド処理を書いてみたよ
こちらにさらにこれをクラスにしたものを掲載しました。
なぜやってみたのか
今回はマルチスレッド処理をC++で書いてみましたのでその紹介になります。
なぜマルチスレッドをしてみようとおもったのか。
それは最近センサの受け取って処理をまわすという部分を書いていて、まじめにマルチスレッドをやる必要があるなと感じたためです。
例えば10msごと(100Hz)にデータが送られてくるものを受け取って、50ms(20Hz)で処理を回したいとなったとき、どういう風に実装するべきでしょうか。
色々と方法はあると思います。
例えば、50msで回したい処理が実際は実行に20ms程度しかかからない場合、
それに加えて受信処理が短い時間で完了するのであれば、割り込み処理で十分かもしれません。
ですが、もし50msで回したい処理が40ms程度かかるものだった場合どういう方法があるでしょうか。
そう考えた時に思いつくのが、処理を複数に分ける(マルチスレッド)ということです。
処理を複数に分けて並行して処理させる"マルチスレッド"とは?
そもそも「スレッド」、「CPU」とは?
そもそも皆さんはパソコンの上で実行されるプログラムはどのようにして動いているかご存じでしょうか。
素子がどのように動くのかという細かい部分はおいておいて、基本的にC++などで書かれたプログラムはCPUで計算、実行されます。
ここでCPUの動きに注目します。
皆さん、パソコンを選ぶ時にこんな言葉を聞いたことはないですか?
- クロック数
- コア数
- スレッド数
これが何か分かりやすく説明してくれているサイトがあるので先に紹介しておきます。
簡単に説明すると、下のようになります。
クロック数 = 頭の回転の速さ (例: 2.0GHz よりも 5.0GHzのCPUの方が計算能力が高い)
コア数 = 何個頭脳を持っているか (例: シングルコア: 1つ、 デュアルコア: 2つ、 クアッドコア: 4つ)
スレッド数 = 各頭脳(コア)が余裕がある時に何個並列で処理ができるか (4コア8スレッドという書き方だと、CPUで余裕があれば2個並列で処理して効率化できる)
すでにお気づきの方もいるかもしれませんが、
CPUの性能というのは一つの項目で決まるのではなく、基本的に上の三つの性能のバランスによって決まってきます。
ではどういう時にどの項目を重視すればいいのでしょうか。
クロック数最重視する場合
ここで処理の話も入ってきますが、例えばそのパソコンでは常にプログラムが1つだけ動くとしましょう。
こうなるとCPUに求められるのは、何よりそのプログラムを早く、安定して回すことになります。
こうなると他に処理をする必要がそもそもないので、コア数やスレッド数は小さくても問題がなくなります。
なので、マイコンなどと呼ばれるような組み込み系のコンピュータはコア数が少なく、シングルコア、デュアルコアが多いです。
(ここではマイコンを例に出しましたが、世の中にシングル、デュアルでそれだけクロック数が高いCPUが出回っていないので、例としては少しずれています)
コア数(あるいはスレッド数)を最重視する場合
例えば処理の重い(各コアの使用率が常に90%近くになるような)プログラムがパソコンの中で3個動くとしましょう。
この時点で察しの通り、上のようなクロック最重視、コア数が少ないものでは3つもの重い処理を回すことができません。
なので、ここではコア数が重要になります。
コア数が最低、その処理を回しきれるだけの数とクロック数を持っているかという確認が必要になるわけです。
(余談) じゃあパソコンを選ぶ時はどういうCPUを選べばいいの?
基本的に用途によりますが、日常的な使い方(ネットサーフィン、メールチェックなど)であれば、正直それほど悩む必要はないでしょう。
予算にもよりますが、Intelなら最低i3 ~ i5、Ryzenなら3以上を選んでおけばそうそう外れることはないでしょう。
(予算があるなら4コア8スレッドで2.0GHz以上のクロック数のものを買うととりあえず後悔はしないと思います。)
(さらに余談) でもパソコンはこれだけでは決まらない
上ではあまり言及しませんでしたが、家庭用パソコンだとCPU以外にもメモリ(一時的に処理しているデータを保存する場所、荷物の仮置き場)、ストレージ(データの倉庫)の二つにも注目する必要がありますので、なかなか決めるのは難しいかもしれません。
なので購入する際には周りの詳しい人に相談しましょう。
ちなみにお店の店員には相談しない方がいいかと思います。お得ですよといわれながら、結構な型落ちのパソコンなどを押し付けられることがあるらしいです。
マルチスレッドとは?
やっと本題です。
マルチスレッドとは、上のCPUの説明である程度察している方もいるかと思いますが、1つのプログラムで複数のスレッド(コア)を使って処理できるようにすることになります。
何がよくなるのかというと、簡単にいうと今まで2.0GHzのコア1つでしか処理ができなかった物が、2.0GHzのコア2つ(あるいはそれ以上)で処理ができるようになります。
なので理論上、プログラムをより高速で(リアルタイムで)実行することが可能になります。
ただし、ここで注意すべきなのは、あくまで理論上可能になるだけで、逆に速度が落ちる可能性もあります。
こういう話でよく聞くのは、最近はやりのGPUプログラミングです。
GPUというのはゲームなどで人や車が3Dで描画されているかと思いますが、その描画をより高速で行うことに特化した演算装置です。
CPUとの一番の違いはクロック数が低いコア数が圧倒的に多い(100倍から1000倍、最近のモデルではそろそろ10000倍になりそう)ことです。
なので、最近のAIやディープラーニングと呼ばれる膨大な並列計算を必要とする技術ではCPUではなくGPUを使って実装しています。
ここまで聞くと速くなる要素しかないですが、落とし穴があります。
それはどのように複数のスレッドに分散するかを決めるところです。
じつは意外と分散して処理をする直前の割り振りを決める処理が重くなって、全体の動作が重くなるということが多々あります。
(最近は優秀なライブラリなどのおかげで減ってきているようですが。。。)
なので、ここで言いたいのは、マルチスレッドをやる前に、「本当にマルチスレッドは必要なのか」、「速くなりそうな処理なのか」を判断する必要があります。
分からないから取り合えずも全然ありだと思います。
なので処理時間で悩まれてマルチスレッドをと考えているそこのあなた、とりあえずまずはシングルスレッドのままで処理の効率化を頑張りましょう!!
本命のソースコード紹介
ここでは上のレポジトリ内にあるudp_pub_test.cpp, udp_sub_test.cppを紹介していきます。
この二つはローカルでUDP通信を行い、pub_testからデータを送信します。
UDP通信についてはまた別の記事で紹介するので、ここでは二つのプログラムの間をUDPっていう通信方式でデータを渡している、とだけイメージしてください。
sub_test側は二つスレッドが立っており、1つは常にデータの受信を待ち続け一定数データが溜まるとデータを読んでいいよフラグを立てます。 もう1つのスレッドは毎ループ、そのフラグを確認し、データが溜まっていればそれを読みに行って、画面に表示するという簡単なプログラムです。
ここでポイントとなるのは以下の二つになります。
- スレッドの立て方
- mutexのかけ方
ソースコードを追いながら順番に説明していきます。
スレッドの立て方
上の概要で説明したように、sub_test側では二つのスレッドが立っています。
- データ受信
- データ解釈
スレッドを立てているのは以下の部分です。 基本的にスレッドを立てる上で使用しているライブラリはC++11にデフォルトで入っている下の二つのライブラリです。
#include <thread> #include <mutex>
int main(void)
{
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(12345);
addr.sin_addr.s_addr = INADDR_ANY;
std::thread th1(ReceivePacket,addr);
std::thread th2(PointPurseMain, 20);
th1.join();
th2.join();
return(0);
}
std::threadで宣言しているのが各スレッドになります。
ここで別スレッドで実行する関数を指定したあと、その下のjoin()関数を実行することで、別スレッドで処理が実行されます。
ちなみに上ではth1でデータ受信の関数名とその引数であるsockaddr_in(UDP通信用)を、th2でデータ解釈をする関数名と引数である関数を回すHz数を与えています。
簡単ですね。
mutexとは?
ここからがマルチスレッドで難しいところです。
マルチスレッドの処理を書いた時に一番陥りがちなのが、メモリのアクセス違反です。(実行時にSegmentation Faultなどとでるエラーです)
これはなぜ起きるのか。
パソコンにはデータを一時保存するメモリと呼ばれる装置が搭載されています。
基本的にプログラムを実行した時の変数だったりはこのメモリに一時保存されます。
メモリの中は賃貸の集合住宅のように区分けされていて、ここはしばらくの間、この変数さんの部屋よ、という形で確保されていきます。
ここで上のアクセス違反という言葉と併せて予想がついた方もいるかと思いますが、この各部屋には一度に一人の人しか出入り(書き込み)できません。
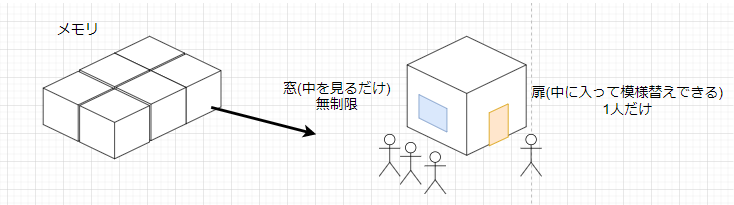
中がショールームのように固定されていて、外から覗くだけであれば人数制限はありません。(いやな世界ですね。。。)
ただし、誰かが部屋の中に入ると、すべての窓はカーテンが閉められ、誰も見てはいけない状態になってしまいます。
あとは簡単ですね。そんな状況で家の中に入ろうとしたら通報されます。(不法侵入or覗きですね)
その通報された結果がSegmentation Faultです。
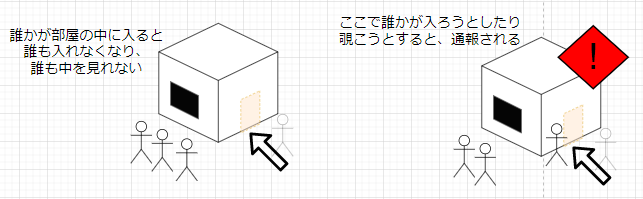
じゃあ、これを防ぐためにどうすればいいのか、それをするのに必要なのが、
- アクセスしていい変数(部屋)を別に用意する
- アクセスする前に誰もいないかの確認をする
の二つになります。
ちなみに後者がここでメインで説明するmutexのことになります。
アクセスしていい変数を別に用意する
関数を見ながら説明していきます。
まず1つ目の説明をするために、データ受信部分を見ていきます。
void ReceivePacket(struct sockaddr_in addr)
{
int sock = socket(AF_INET, SOCK_DGRAM, 0);
bind(sock, (struct sockaddr *)&addr, sizeof(addr));
uint8_t tmp_buf[BUFFER_SIZE];
uint8_t* p = tmp_buf;
int point_num = 0;
int point_limit = POINT_BUFFER_LIMIT;
int point_size = SINGLE_POINT_DATA_SIZE;
int point_id = 1;
while(1)
{
recv( sock, tmp_buf, sizeof(tmp_buf), 0);
memcpy( p, tmp_buf, point_size);
p += point_size;
point_num++;
if(point_num > point_limit)
{
printf("Receive Func:PointLimit\n");
std::lock_guard<std::mutex> lock(mtx_);
memset(buf_, 0 , sizeof(buf_));
memcpy(buf_, tmp_buf, point_num * point_size);
memset(tmp_buf, 0, sizeof(tmp_buf));
p = tmp_buf;
point_num = 0;
data_set_flag_ = true;
}
}
close(sock);
}
内容はいたってシンプルです。
毎ループ、データが来るのを待って、データが来たらそれをBuffer(データを格納するスペース)にポコポコ入れてあげるだけです。
そのあとに一定数データが溜まったら上で書いたフラグを立てた上で、アクセスするようの別のBufferにコピーします。
そうここでコピーしている先の別のBufferが上にあげた1つ目になります。
ただ、こちらについては必須ではありません。
先ほど話したように、各メモリの書き換えができるのは一度に1つのみです。
なので、他のスレッドがアクセスしている間、そのメモリにアクセスしないのであれば、こちらのように別にBufferを用意する必要はありません。
作業中他の人をアクセスできなくする、アクセスする前に誰がいるかを確認する(mutex)
イメージは各メモリ(部屋)に入る扉に、在室、退室の看板が立っているイメージです。
入る時は在室にして、出る時は退室にしましょう。入る前には看板を確認して、在室になっていたら待ちましょう。
mutexはただそれを簡単に行ってくれるだけです。
では簡単にソースコードを見ながら簡単に説明していきます。次に見ていくのは解釈部分です。
void PointPurseMain( int hz )
{
std::chrono::system_clock::time_point start, now;
start = std::chrono::system_clock::now();
now = std::chrono::system_clock::now();
double now_process_time = std::chrono::duration_cast<std::chrono::milliseconds>(now-start).count();// to milliseconds
double process_target_time = 1000 / (double)hz;
int process_time = 0;
int point_num = POINT_BUFFER_LIMIT;
int point_size = SINGLE_POINT_DATA_SIZE;
int point_id;
while(1)
{
std::lock_guard<std::mutex> lock(mtx_);
if(data_set_flag_)
{
for(int i=0; i<point_num; i++)
{
point_id = i;
printf("Main Thread:%d of points are set!! %d th point is (%d, %d, %d, %d)\n",
point_num,
point_id,
buf_[0 + point_size * point_id],
buf_[1 + point_size * point_id],
buf_[2 + point_size * point_id],
buf_[3 + point_size * point_id]);
}
data_set_flag_ = false;
}
now = std::chrono::system_clock::now();
now_process_time = std::chrono::duration_cast<std::chrono::milliseconds>(now-start).count();
process_time = (int)(process_target_time - now_process_time);
if(process_time > 0)
{
std::this_thread::sleep_for(std::chrono::milliseconds(process_time));
start = std::chrono::system_clock::now();
}
}
}
ここで重要なのはこれです。
std::lock_guard<std::mutex> lock(mtx_);
上の受信関数でも呼ばれていましたが、この一行を呼ぶことでメモリの入口前の看板を確認し、退室になっていれば在室にした上でアクセスを始めます。
引数で与えている"mtx_"はグローバル変数で頭で宣言しています。
なので、これらのポイントを抑えることで簡単にマルチスレッド処理を書くことができます。
ちなみに二つターミナルを開いて、片側でudp_sub_test, もう一方でudp_pub_testを実行すると以下のように画面に出力されます。
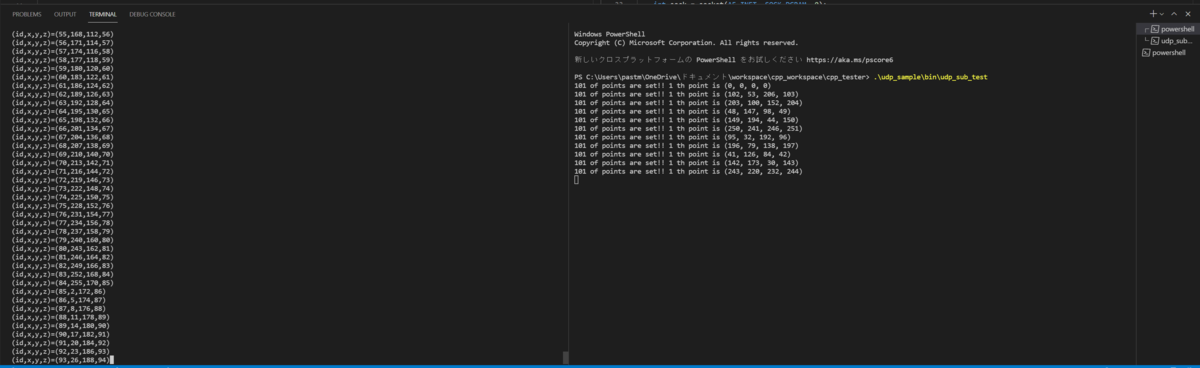
これでちゃんと動いていることがわかりますね。
まとめ
というわけでマルチスレッド処理をC++で書いてみました。
組み込み系をやっている人間として、処理速度に困ったとき最後の砦として存在するマルチスレッドを勉強してみましたが、意外と簡単に書けるなという印象です。
是非とも皆さんも試してみてください!!
ではでは。